30 Principles of Epidemiology in Rheumatic Disease
Overview of Epidemiologic Methods
Epidemiology is the study of the distribution of disease and its determinants in populations.1 Its purpose is to describe the frequency of disease and to determine causes responsible for variation in disease occurrence. Comparison of the relative strengths of those causes and assessment of their generalizability can allow “truth” to be inferred. This chapter explains basic epidemiologic concepts and definitions; describes the major study designs, their strengths and weaknesses, and their usefulness in inferring causality; and demonstrates specific applications of these principles to the study of rheumatic diseases. For the purposes of this chapter, the term disease is used to represent a disease, death, or other health outcome of interest, and the term exposure is used to represent a risk or protective factor examined for its association with disease.
Measures of Disease Occurrence
Incidence
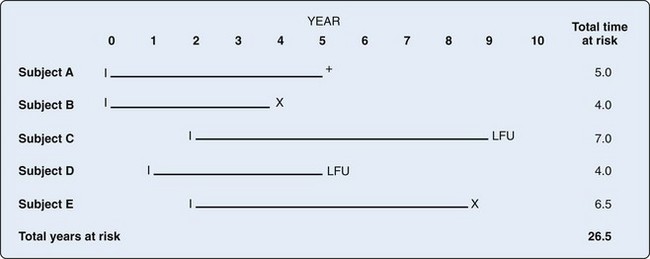
In order to determine the likelihood that disease will develop over time, repeated observations of the same people are required to determine who develops disease and who does not. Incidence proportion, or risk, is the frequency of new cases over a specified time, out of those at risk for, but without, the disease at baseline. During the observation period, a person may be at risk for the disease but not develop it, and he or she would contribute time at risk for the entire period. Alternatively, a person may develop the disease in question, die from competing risks, or be lost to follow-up. All of these situations result in that person’s no longer contributing time at risk to the denominator. The concept of person-time includes the actual time at risk contributed by each individual. For example, consider the hypothetical example of incidence of systemic lupus erythematosus (SLE) over a 10-year period (Figure 30-1). Person A may not develop the disease during the observation period but may die at Year 5 of a competing cause; this person contributes 5 person-years to the denominator. Person B might develop SLE 4 years after the study begins and thus is no longer at risk of developing the disease; this person contributes 4 person-years of time at risk to the denominator. Person C joins the study at Year 2 and is lost to follow-up at Year 9, contributing 7 years of time at risk. Person D joins the study at Year 1 and is lost to follow-up at Year 5 for a total of 4 years of person-time at risk. Person E joins the study at Year 2 and develops SLE halfway between Year 8 and Year 9, contributing 6.5 person-years at risk. Incidence rate is defined by the following2:
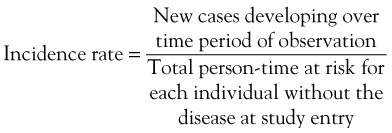
Study Designs
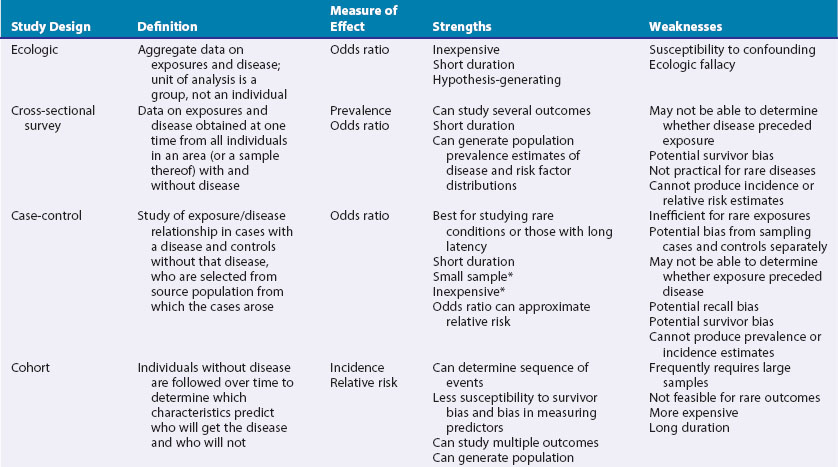
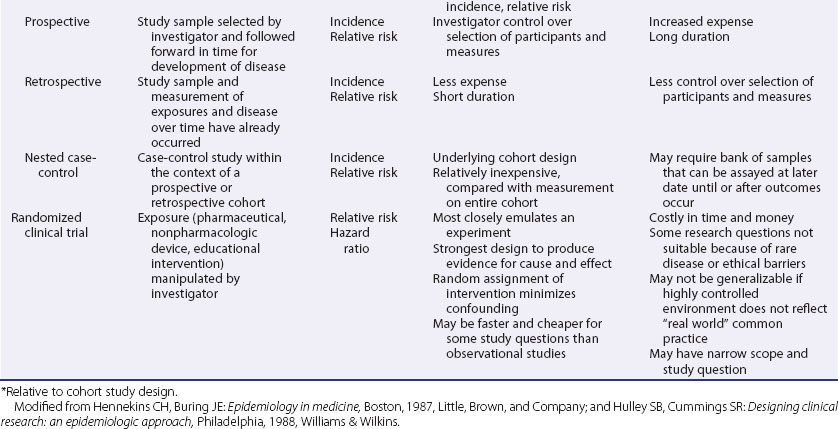
These include ecologic studies, cross-sectional surveys, case-control studies, cohort studies, and randomized controlled clinical trials—the last frequently considered the most rigorous study design and the one most closely representing a formal experiment. Each study design has its own inherent strengths and weaknesses (Table 30-1), and the choice of study design depends on the research question, the rarity of the disease under study, the availability of appropriate study and comparable control populations, resources available to conduct the study, and logistics.2,3
Observational Studies
In observational studies the exposure is not randomly distributed in a population. The investigator observes the exposure rather than selects the exposure status of an individual.4 Types of observational studies include ecologic, cross-sectional, case-control, and cohort.
Ecologic Studies
In the ecologic study design, the unit of observation is a group, rather than an individual.5 Aggregate data on rates of disease and risk factors are compared to examine associations between disease frequencies and exposures. The ecologic study is frequently a design of expediency and can generate hypotheses for more rigorous testing in studies using individual-level data.3 One of its chief drawbacks is its high susceptibility to confounding. This occurs when an extraneous factor, not on the causal pathway, masks the true relationship between exposure and disease, by virtue of its association with both.6 Further, associations in the aggregate may not necessarily hold for the individual.3 This concept is termed the ecologic fallacy. As a hypothetical example, rates of specific kinds of cancers may be higher in countries in which cigarette sales are also high. Whether those who are buying, and presumably smoking, the cigarettes are the same persons who develop cancer is not known from this study design.
Cross-Sectional Surveys
The goal of this study design is usually descriptive including all individuals, with and without the disease under study, in the population or a representative sample of them, at one point in time with no follow-up period. Surveys can estimate prevalence of a particular disease in the population and determine the need for health services and resource allocation.3 Typically, information about risk factors is obtained simultaneously. Such risk factor data may or may not represent the most relevant time of exposure, nor can it be determined whether the exposure preceded or resulted from the disease.2
An example of a cross-sectional survey, conducted approximately once per decade in the United States, is the National Health and Nutrition Examination Survey. This survey samples a proportion of the residents in the contiguous 48 states and measures various health outcomes and habits such as blood pressure, serum lipids, height, weight, smoking, and dietary intake. These surveys have been used in rheumatology to determine the prevalence of radiographic knee and hip osteoarthritis (OA) in various age, sex, and race/ethnicity subgroups.7
Case-Control Studies
Strictly defined, the case-control study is a study in which those with the disease (cases) are compared with a control population without the disease, drawn from the same source population from which the cases arose.1,6 The source population may be the residents of a particular geographic area or a hospital’s referral base. The control group serves as an estimate of the distribution of the exposure in the source population, and consequently, the control group must be sampled independently of exposure status.1,6 For example, if one is interested in examining the possible association between smoking and progressive systemic sclerosis (PSS), the controls must be from the same source population that generated the cases, if this can be determined, and must be sampled without regard to their smoking status.
Selection of Controls for Case-Control Study
If the source of the cases is a well-defined population, the controls can be sampled directly from that population. If the source population is too large to allow a complete enumeration, controls may be matched to each case by their residence in the same neighborhood. Random-digit dialing can be used to select controls, but this labor-intensive method omits from selection those without telephones or those who cannot be reached.1 If the cases are drawn from a particular hospital or clinic, then the source population should represent people who would be treated in that hospital or clinic if they developed the disease under study, but frequently, this source population can be difficult to identify and is influenced by referral practices.1 Hospital or clinic controls can be used, but this method can have particular pitfalls because the controls might not be selected independently of the exposure in the source population. For instance, in a hospital-based study of smoking in SLE, individuals hospitalized for other diseases such as myocardial infarction or pneumonia might have exposures different from the source population in general, especially if the exposure, in this case smoking, causes or prevents the “control” disease selected. One way to avoid this is to exclude diseases known to be associated with the exposure under study, but this may create other biases. Another tactic could be to select hospital controls with diseases that are felt to be unrelated to the disease or exposures under study such as traumatic leg fractures1 or to use several control groups selected differently.3 The latter example might sample controls from hospitalized patients with other diseases than the disease under study, nonhospitalized patients in the same medical care system, or nonhospitalized individuals in the general population, comparing each control group separately with the diseased group.
Weaknesses of the Case-Control Design
It is not possible to derive incidence or prevalence estimates from a case-control study. The greatest threat to validity is the inherent susceptibility to bias that can exist in this study design, because the cases and controls are sampled separately and the assessment of exposure variables is retrospective.3 Matching the cases and controls on factors such as age, sex, or race/ethnicity can help ensure comparability of cases and controls to a degree. As mentioned earlier, more than one control group, selected in different ways, can be used to see if findings are consistent across control groups with different sampling biases. A nested case-control design, in which a case-control study is performed within a larger cohort study, has the advantage of minimizing sampling bias because the cases and the controls would have been previously sampled in identical fashion into the parent cohort study.3
The other chief source of bias in the case-control study is recall bias, which occurs when exposures predating the disease may be differentially reported by the controls and the cases, the latter of whom may have incentive to remember and report exposures. This can be partially prevented by using exposure data measured before the disease occurred, if available, and by blinding the observer and the subject to the exposure under investigation or, if possible, blinding them even to the specific disease under study and therefore to case or control status. For example, in a case-control study examining racial/ethnic variation as the exposure variable of interest in SLE, race/ethnicity is immutable and therefore not subject to recall bias. In contrast, if study participants know or suspect that prior exposure to hair dye, for instance, is the exposure of interest in the same case-control study, those with disease may be more prone to “remember” their exposure than might those without disease. Investigators can obtain information about multiple potential exposures or even include several “dummy” exposures to mask the real hypothesis to try to minimize this type of bias.8





Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


