33 Assessment of Health Outcomes
Any single health outcome can only provide a particular view of the impact of a disease on a person.
Defining the measurement need is the key to the choice of the right instrument.
In an era of rising health care costs, greater provider accountability,1 and an increased emphasis on decision making based on patient-reported outcomes,2,3 the capacity to discern the best outcomes and the best instruments has become a skill needed by researchers, clinicians, and funding bodies. By one definition, health outcomes refer to “all possible effects of a disease or intervention,”4 in our case for a disease like arthritis and the end points used to evaluate its treatment. In addition, there are biomarkers that “mark” a biologic process (e.g., decreased inflammation) and have some relation to health outcome. In a few instances, biomarkers can be regarded as surrogate outcome measures where the relationship with outcome (and change in outcome) is strong, and interventions that target the biomarker result in improved health outcome.5 Other chapters in this text refer to some of the most common instruments of health outcome and disease encountered in rheumatology such as the Disease Activity Scale (DAS, DAS28),6 the Health Assessment Questionnaire (HAQ),7 and the SF-36.8 Many more instruments of this type exist, but how different are they? Why do we need to choose so carefully? Using any one of these health outcome assessments is like looking out a window in a house, and the burden of arthritis is the landscape outside. From any one window there is a view of the outside world, but it is a specific view defined by the size of the window and the side of the house it is on. Another window may offer a slightly better perspective on what one would like to see. Different health outcome assessments can have a degree of overlap in their views, in which case an informed choice will need to be made between them, whereas others can hold quite distinct views. Although one outcome assessment might be useful to compare the burden of arthritis against the general population, another might be better for measuring the specific benefits of an arthritis intervention. No one instrument fulfills all requirements. To carry forward the metaphor of a window, once it is clear whether that instrument can offer a view of the target concept, one must also make sure the view is clear, precise, and consistent each time any person looks through that window—attributes that are shown by the validity and reliability of a scale. This chapter focuses on describing the different windows we have on the burden of arthritis and how they relate to each other. We then provide a framework for ensuring that a selected instrument is the right one for a given need. This chapter therefore addresses three questions: Which health outcomes assessment instruments are available, both generally and specifically, for use in rheumatology? How does one know what one needs to measure? How does one find an instrument that can meet that need?
Which Health Outcomes Assessment Instruments are Available?
Disease-Specific Instruments: Core Sets
Core sets are the minimal, but not exclusive, set of domains to be measured in a study of arthritis. Historically, they follow the Ds of outcome measurement in arthritis: disability, disease activity, damage, discomfort, dissatisfaction, and death.9,10 They are usually recommended by groups such as Outcome Measures in Rheumatology (OMERACT), the European League Against Rheumatism (EULAR), International League of Associations for Rheumatology (ILAR), and American College of Rheumatology (ACR) or by groups formed around specific diseases such as the Assessment for Ankylosing Spondylitis (ASAS) and the Group for Research and Assessment of Psoriasis and Psoriatic Arthritis (GRAPPA). All have an interest in agreeing on a common set of relevant and psychometrically sound outcomes that would allow them to compare findings across studies and modalities of clinical care. Table 33-1 shows core sets for clinical trials in nine types of arthritis.10–24 It also shows what each group recommends as additional domains or as needing more research before they become core set members. Some groups such as systemic sclerosis are moving through the refinement of their core domains.25 The first column in this table represents Wolfe’s broad core set for longitudinal observational studies in rheumatology10 with some minor additions. Wolfe and colleagues’ list is longer than the other columns because observational studies are often looking for a broader range of outcomes than treatment trials. It is also designed to be used across different forms of arthritis. The Wolfe set therefore serves the broader list of outcomes against which we can describe what is also included in the more focused core sets. The remaining columns show that across different types of rheumatic diseases, the core sets have many common elements—most contain or recommend pain, physical function, patient and clinician global assessments, and markers of inflammation. Many also include disease activity and/or damage indices, which are often an aggregation of other clinical findings (e.g., joint count, acute phase reactants, global ratings of severity) into a score reflecting the activity of the disease at that point in time. Some core sets contain domains reflecting the unique aspects of the disease (e.g., spinal mobility in ankylosing spondylitis)26 or the unique target of the study (e.g., tophi in measuring response in gout).23
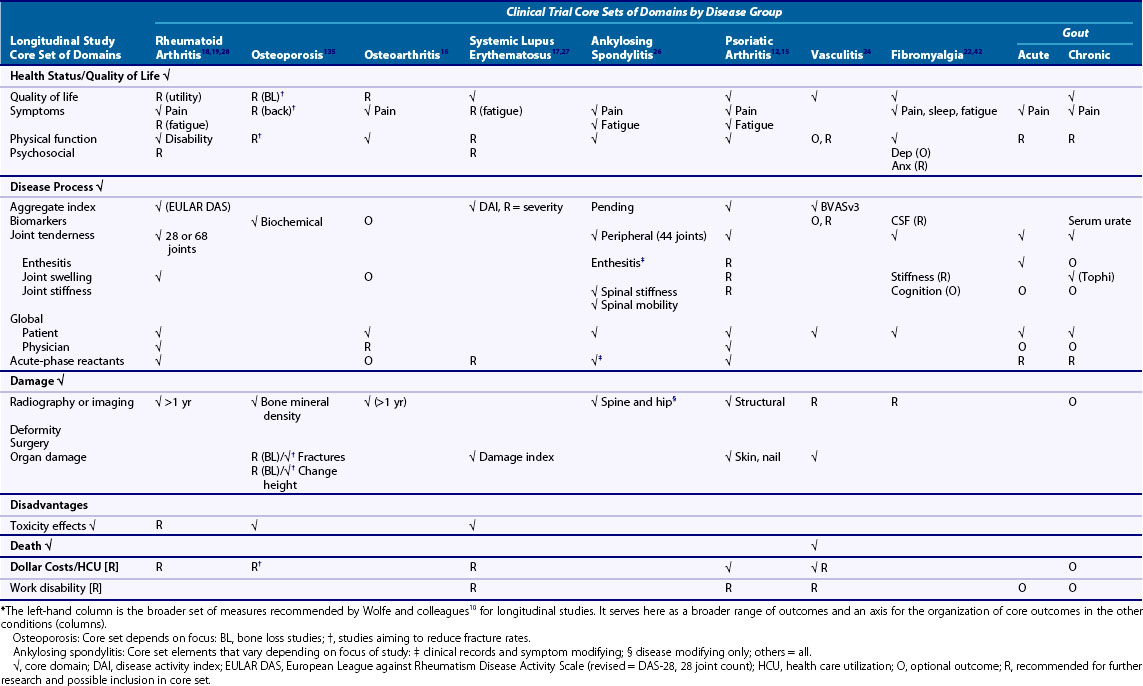
Table 33-1 focuses on the core domains that should be measured. The next step is to decide on the instrument(s) that will be able to provide that information in a reproducible, accurate manner. In some cases an instrument choice has been suggested (e.g., the HAQ for disability in rheumatoid arthritis [RA]). In other instances, several options are provided. Strand reviewed six disease activity indices in lupus and found that they gave comparable results.27 In some cases, the domains are shared but the measurement technique varies within or by disease—in RA the DAS28 uses 28 joints,6 whereas in ankylosing spondylitis 44 joints are counted.26 We briefly review some of the more commonly encountered instruments in arthritis.
Health Status/Quality of Life
General Health Status
Generic health outcomes provide information on an aspect of health across many conditions, so theoretically comparisons can be made to compare the burden of low back pain with that of arthritis or diabetes. This depends on how well an instrument captures the burden in a disease group. Generic instruments have the advantage of allowing comparisons across diseases and covering a broader range of health issues, which may otherwise be overlooked in a core set (e.g., mental health). However, generic instruments, due to their breadth, tend not to delve sufficiently into the depth of experience in any one disease. Arthritis-related fatigue, for example, is not picked up well in many generic instruments because they ask about “being tired” or “not sleeping well,” rather than the pervasive nature of exhaustion described by patients with arthritis.28 As a result, they are usually weaker in their ability to detect specific changes and their sensitivity to different levels of disease activity may be low. They should, therefore, usually be supplemented with disease-specific instruments.29
Two of the more commonly used generic instruments are the Sickness Impact Profile (SIP)30 and the SF-36 (short form, 36 items).31 The SIP is a 136-item list of illness behaviors that provide a weighted score for the impact of a disease across 12 categories such as bodily pain, work and role functioning, and dressing,30 which lead to global scores as well (physical, psychosocial, and overall). The SIP has been shown to measure illness across a wide variety of health conditions.29 The SF-36 is a 36-item questionnaire of which 35 items are used to obtain 8 domain scores including physical functioning, mental health, role functioning, and pain. It is scored on a 0 to 100 scale (100 = better health)31 and two summary scores (mental and physical) that are scored with a normal of 50 and standard deviation of 10. The SF-36 and the briefer SF-12 are supported on the website www.qualitymetric.com and through manuals that supply age- and disease-group distributions of scores.32 Direct comparisons of generic instruments have shown differences in scores and health states attributable to the choice of instrument.33–35 Studies or clinical results may not be comparable with each other if they are using different health status scales.
Utilities: Value of Health State
Utility scales offer an overall score for the value of a health state, setting death at zero and full health at one. The emphasis is not on describing the state but on assigning a value, worth, or preference to that state.36,37 Utilities are necessary for economic appraisals and form the health assessment for cost per (quality-adjusted life years) QALY estimations. Utility states can be obtained by direct or indirect methods. Direct methods such as standard gamble and time trade-off involve the respondent working through exercises to elicit the value for his or her own health state against elements like time, or more/less favorable health situations.36 Indirect methods capture the state with standardized questions and then apply predetermined weights.37 Examples include the EQ-5D, which comprises five items (three response categories) combined to describe a health state. Similarly, the Health Utility Index (HUI) gathers information on six or seven dimensions of health (depending on the version) on five-item to six-item response scales to define a health state.37 Both forms, along with the increasingly popular Short-Form Six-Dimensions (SF-6D) utility index,38 then use weights determined in different populations to assign the value to these health states, hence the “indirect” weighting. The absolute values obtained across these different approaches will vary.36,39
Symptoms
Pain is usually measured using a 10-cm visual analog scale or a 0- to 10-point numeric rating scale of the intensity of the pain.40 These scales, simple instruments, have been well tested and are easily understood by patients. Fatigue is another important symptom, which many patients feel is quite distinct from being “tired.”41 Teams are recommending either global indices or one of several available scales that were reviewed by OMERACT attendees.42–44 Work done at OMERACT on the measurement of problems with sleep provides a recent strong example of moving through the concept of impairment of sleep, defining it, and then focusing on the available scales that capture that concept and definition.45,46
Disability Scales
Physical disability caused by RA or osteoarthritis is often measured using the Health Assessment Questionnaire–Disability Index (HAQ-DI),47 which covers 20 items examining different domains of daily functioning. Patients score each item on a 0- to 3-point scale, where 3 represents the greatest disability. Scores are obtained for each domain and then combined for a total score expressed on the same 0- to 3-point scale. Scores are adjusted to a worse health state (a 2/3) if a support is used to complete a task. More details on the HAQ-DI are widely available in print and on the Internet.
Other scales or subscales assess physical function such as within the Arthritis Impact Measurement Scale (AIMS)48 and the AIMS2,49 as well as measures with even more specific foci such as the Western Ontario and McMaster osteoarthritis index (WOMAC), which is commonly used in hip and knee osteoarthritis50 and the AUSCAN (Australian-Canadian) osteoarthritis index for hand osteoarthritis (OA).51
Disease Process (Activity, Severity)
Core sets often include indices of disease process, which can be divided into activity (inflammatory activity) and severity (overall severity of disease) measures. There are several disease activity indices, the most commonly used being the Disease Activity Scale (DAS)52 and DAS286 in RA. A subset of the core outcomes (i.e., acute-phase reactants, joint counts, global ratings) was combined to form a weighted score that provides a score of 2 to 10 (DAS) or 0 to 9 (DAS28). Based on these scores, cutoffs were established to define high, moderate, and low disease states. Until recently the low disease state (DAS28 < 2.6) was considered an indicator of remission of arthritis. This is revisited later. Also recently, new criteria for remission in RA have been proposed. In these, the use of the DAS has been abandoned because it allows significant residual disease activity even at low values.53 Disease activity indices track the level of inflammatory activity. Other examples of disease activity indices include the Bath Ankylosing Spondylitis Disease Activity Index (BASDAI)54 and the six available for lupus.27 When more than one is available, it is helpful to seek direct comparisons of instruments such as that performed by Strand to evaluate comparable information.27,55 Work is also under way to focus on an evidence-based, consensus-driven definition for a flare or worsening of arthritis56 to use in clinical trials to describe a worsening rather than improving situation.
Damage Indices
Damage indices are indicators of structural damage to joints, typically shown by joint space narrowing, erosions, subchondral cysts, or osteophytes. In RA, particular attention has been paid to this by van der Heijde, who reviews three approaches (Sharp, Larsen/Scott, and van der Heijde) that are used to assess joint damage and progression in joint damage.26 Progression is usually measured using the “smallest detectable change” that is determined by the threshold or error associated with the amount of variability in radiographic measurement between observers.57,58
Toxicity/Adverse Events (Wolfe’s “Disadvantage” Category)
Medical and nonmedical management of many rheumatic conditions carries a risk of toxicity and adverse events,59 many of them unexpected. Because patients, clinicians, and policy makers want to balance benefits versus harms when considering intervention, comprehensive documentation of a range of adverse events is important in outcomes assessments separate from the treatment benefits.60 An OMERACT group is currently working on standardizing reporting of toxicities in rheumatologic trials.61,62
Dollar Costs
Given that resources are always limited, together with the benefits and harms, the costs (e.g., dollar costs) of a treatment are also considered an important outcome. Harmonization is important in order to get a comparable estimate of cost across studies.63 Several groups are working toward developing a formula for quantifying the costs associated with arthritis and with its treatment at the time of writing.
Other Outcomes of Interest
Self-Efficacy/Effective Consumer
Self-management is becoming incorporated into programs for persons with many chronic conditions. For patients with arthritis, these programs have been shown to improve levels of self-efficacy; that is, the confidence one has in one’s ability to manage pain and disease effectively. Lorig’s Self-Efficacy Scale is one of the most commonly used outcomes for this type of study.64 Tugwell’s group has developed a companion to this, the “effective consumer scale,” which captures the degree to which the patient is effectively managing his or her own health care decisions, interactions with the health care team, and disease monitoring.65 It is an instrument with demonstrated reliability, validity, and responsiveness in arthritis66 and has the support of consumers with arthritis.41
Work Disability: Looking beyond Absenteeism
With the shift toward more aggressive management of earlier rheumatic disease, more people with arthritis are working and outcomes need to shift to track work disability more comprehensively (absenteeism and at-work productivity loss).10,41,67 Work is difficult to measure because it depends on the job and the organization in which an individual works. Absenteeism can mean many things, and instruments should articulate how it is operationalized such as full days off work, days on insurance payments, or partial days off work. More challenging still is measuring the difficulty someone is having at work (presenteeism). In a recent review we found more than 20 instruments available.68 The most commonly used in arthritis is the Work Limitations Questionnaire (amount of time experiencing difficulty69). Two scales developed in arthritis are promising: Gignac’s Work Activity Limitations Scale70 (amount of difficulty experienced) and Gilworth’s Work Instability Scale (captures risk of future work loss).71 The Work Productivity Scale for Rheumatoid Arthritis has been used in clinical trials and captures worker productivity on a global index, as well as nonpaid work (see next section).72–74 Direct comparisons of instruments show differences in their performance that primarily relate to the variant of the construct they are measuring.75
Nonpaid Work Roles
Participation in valued nonpaid roles such as parenting, volunteer work, or leisure activities can be important aspects of the burden of disease.76 Outcome instruments reflecting this are necessary in order to fully capture the concept of participation as described by the International Classification of Functioning (ICF).77
Patient-Specific Indices
Patient-specific scales including the MACTAR or PET in arthritis78,79 allow the patient to nominate his or her own scale content within a guided framework. Most patients report three to five items that are particularly salient to them. A surprising number of these scales have been developed.80,81 Each taps relevant content for patients, and because of this they are also responsive to change.82 The challenge is in the mathematics and how to analyze the numeric score that is so dependent on each individual’s own items across patients (group level mean or average score has little meaning). Analysis that focuses on individual level quantification is likely best (e.g., percent of people reaching their goal, improving in their selected activities).
Satisfaction with Health Outcomes
Satisfaction scales are often linked with the goals of a health care organization and focus on the attributes of the structure and process of care (e.g., length of wait, professionalism of staff). However, instruments developed to look at satisfaction with a specific health end point (i.e., how satisfied are you with the results of your surgery?)83 become a health outcome. Satisfaction with outcome is complex, and Hudak and colleagues remind us of the complex balance between experiences and ability to “live with” ongoing limitations that influence a patient’s response.84 However, it may be worth the effort in order to report all outcomes that are meaningful to the patients.
How To Determine What to Measure: Defining One’s Measurement Need
What Is Worth Measuring?
Defining a need is not always as easy as it might seem. What is health? What about pain? In recent years, there has been a shift in the outcomes toward a more patient-centered focus both from a health systems and political point of view, reinforcing and, indeed, legislating the importance of patient-centered care and outcomes.2,3,43,85
With such a focus, the role of patient as partners in research and outcome definition becomes even more important. Partnerships with patients have opened many doors to improved outcome measurement. There is no better source of information on the nature of a symptom experience or the impact of arthritis on something like work67 or fatigue.44 The patient experience of disease can complement that of the researcher. The idea is that research grounded in relevant clinical need, patients’ perspectives, and patients’ priorities will enhance study design, practicality, recruitment, data interpretation, and dissemination. In addition, the reporting of the research results will most likely be more meaningful to patients because it will be done in terms that the patient understands and that are relevant to the patient.3,86 In outcome measurement, rheumatology has been in a leading position since the inclusion of patient partners (as experts in the experience of arthritis) at OMERACT conferences from 2002 onward. Perhaps the most concrete example of the impact of the patients’ perspective has been the recommendation by OMERACT to include the measurement of fatigue in the core set of measures for clinical trials in RA.44 Subsequently, work has focused both on other important aspects such as measurement of sleep quality and more method-oriented topics such as how to rigorously develop new patient-reported outcome measures. Groups such as EULAR or the U.S. Food and Drug Administration have made the involvement of the patient in the development of patient-reported outcomes an essential feature for new scales60 (e.g., as seen in the development of RAID [Rheumatoid Arthritis Impact of Disease]).87 Involving patients in research has several challenges that include practical issues such as overcoming access, communication barriers, establishment of a new professional relationship while continuing in a doctor-patient relationship, confidentiality issues, and training in science methodology and nomenclature.88 It is expected that patient or consumer involvement will become a standard feature in clinical and outcomes research and that methods of engagement will continue to evolve.
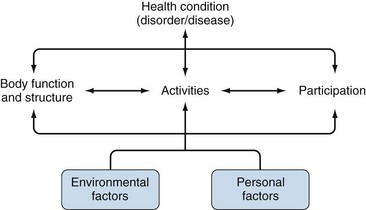
Defining key concepts or outcomes may also be facilitated through use of conceptual frameworks. Conceptual frameworks offer definitions of their key concepts and discuss how a construct relates to other variables in their model. One increasingly popular framework is the International Classification of Functioning (ICF) endorsed by the World Health Organization in 2001. The ICF framework (Figure 33-1) describes three main concepts: impairments (symptoms, structural limitations); activity limitations (difficulties while performing tasks); and participation restrictions (social role participation). Also important are environmental factors (e.g., job demands, environmental barriers, weather) and personal factors (predispositions, coping strategies). Other frameworks include the Verbrugge disablement process, which has slightly different concepts along its main pathway,89 and the Wilson and Cleary framework.90 Both of these frameworks define a main pathway from cellular findings to a broad level of disability or quality of life. Personal and environmental factors are also present in these models, but more as effect modifiers rather than as an essential part of the concept. Importantly, they also differ from the ICF in terms of the definition of “disability,” for example, reinforcing the need to be explicit about not only the concept but also the framework from which one’s definition comes. An alternative definition for physical functioning at the level of disability is described by Verbrugge.89 Similarly, when measuring pain, is intensity more important than frequency to patients? What about the degree to which pain interferes with daily activities? Conceptual frameworks define the realm of outcomes that should be considered and the hypothetical relationships between them. They form the basis for understanding our observations, testing hypotheses, or planning and executing an analysis. Choosing a framework that helps one to define and think about the concept one wants to measure will be helpful down the road when trying to understand the findings. Working across different frameworks or trying to fit an instrument into another framework is challenging because different instruments may vary in how they define certain aspects of health or disability. However, shifts to a new framework can prompt fruitful rethinking of concepts and how they relate to each other.91
Why Measure?
Clarity about an instrument’s intended purpose will help ensure the right one is selected. Kirshner and Guyatt describe three purposes: descriptive (measure a concept at one point in time such as the burden of illness), predictive (provide information about the future such as the HAQ predicting mortality in arthritis), and evaluative (measure change over time such as the benefit or harm from treatment).92 Each purpose requires evidence of certain measurement properties of the candidate instrument. In this chapter we focus on the purposes relevant to health outcome assessment: describing an end point state in a trial at one point in time (Kirshner’s descriptive purpose) and evaluating the amount of change experienced over time (Kirshner’s evaluative purpose). The purpose dictates the type of evidence to focus on when making a decision about a given instrument.92
Who Comprises the Target Population?
The target population is critical but often overlooked. A given instrument may, for example, work well in severe OA of the hip but not be sensitive to the early symptoms of the disease. It is equally important to consider if one wants to measure for an individual patient or describe a group of patients as a whole, for example, in a clinical trial. The former demands much higher levels of measurement properties such as reliability coefficients greater than 0.90 as opposed to a minimum of 0.75 to 0.80 for group descriptions).93
Decision-Making Instrument for Selecting the Outcome that Can Meet THE Measurement Need
The selection of an outcome measure depends entirely on a clear understanding of measurement need. All too often a commonly used instrument is selected rather than looking for one that matches the concept, population, and purpose. Once the measurement need is defined, the users should begin on a decision-making process that helps guide the final decision. Many guidelines that offer more detail than can be provided here, particularly for the acceptable levels of reliability and validity, are available.93–99 What we describe here is a decision-making process that can be used to assess if a given instrument fits with the articulated measurement need. This process, depicted in Figure 33-2, builds on the work of Law99 and the OMERACT filter.96 It also highlights key concepts in each area from the published guidelines.
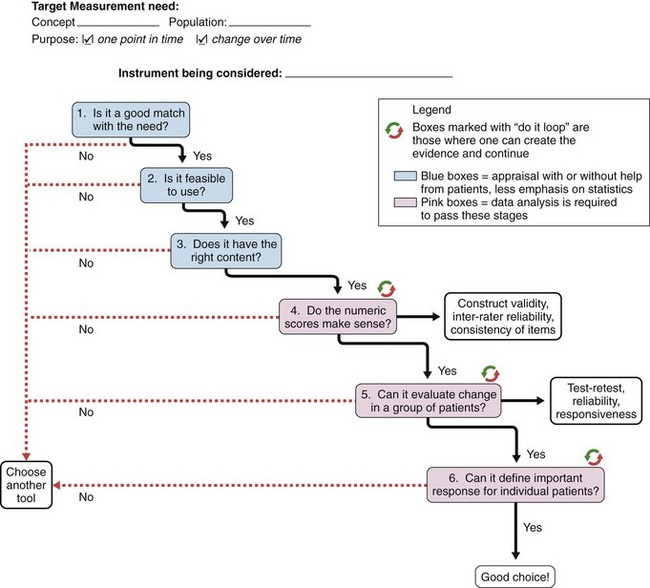
Step 1: Is It a Good Match with the Need?
Think about the concept and then decide based on the description of the candidate instrument and the nature of the items whether there is a match between the instrument’s concept and the measurement need (concept, population, purpose). An operational definition of the target concept, the applicable populations (specific patient group or general population), and intended purpose should be articulated by the developer and match the current need.60,98,100 If it is not there or if it is not a good match, start with another candidate instrument because this one will not work.95 For example, the target might be physical function and the instrument only covers physical function briefly but includes more on emotional and social health and is even in use in the research community. If the concept is not a clear match with the target, pass it by.
Step 2: Is It Feasible to Use?
Feasibility covers the practical aspects of using this scale in the intended setting.96,99,100 Does it take too much time? Are the licensing costs too high? Does it require special equipment? Is it too burdensome for patients (language, literacy, acceptability of questions)? Is it formatted well on the page, and do the responses make sense given the target and the question? Are the questions phrased in a clear and simple manner? Are the necessary scoring instructions available? Are the results of the score easily interpretable? A negative to any of these could direct one to go to another, more feasible instrument. Feasibility often makes or breaks a decision about a candidate instrument.96 Others might call this “sensibility” or “clinical usefulness” of an instrument. Usually the appraisal is completed by the investigator, but more insight can be gained by including patients’ input into the length, difficulty, and burden of the questionnaire.
Step 3: Does the Instrument Look Like It Has the Right Content in Order to Measure What It Is Intended to Measure (Truth 1)?
Over the course of the decision-making process, one will see much emphasis on the truth part of the OMERACT filter.96 This level of “truth” describes content validity. Does it appear that the candidate instrument is covering the domains of the concept well, and do the items align in this content? This, like step 2, is usually done by the clinicians or researchers, but patients can also provide valuable insight into ensuring the content is comprehensive.
Content validity appraises the items and domains of a scale, as well as whether the authors have covered the breadth and depth of the concept.93 In other words, are all the important areas covered, and is there enough depth to capture the range of experience of the patients? Face validity is an appraisal of the general direction of the scale; will it hit the target? Are the response options organized in a logical direction for high and low levels of this attribute? Does the scoring make sense?
Step 4: Do the Numeric Scores Make Sense? Are These Scores Behaving in Ways That a “Good” Measure of This Construct Would Behave (Truth 2)?
Construct validity is generally measured by comparisons with other similar scales or related constructs (i.e., high and low levels of pain and function). Theoretical situations are established before analysis, the direction and magnitude of the expected relationship are declared, and then the relationship is tested.95,100,101 Comparisons should also be made between groups known to differ (high vs. low severity) or with scales where no relationship is found. Again, this is based on an a priori theory checking to see if the candidate instrument behaves according to the theory. These comparisons add to the evidence that the instrument is measuring what it is supposed to measure.95 If the evidence is not available or not available for the intended population, one has the choice of abandoning the instrument or conducting a study to create that evidence and then continuing to advance.
Construct validity can also be assessed looking at the structure of a scale. If a scale (or subscale) is set up to measure one construct, all the items should “load” onto that one factor. That is, they should be highly correlated with each other enough that together they seem to belong to an underlying trait like health, pain, or anxiety. We assess this structural validity through approaches such as factor analysis (if the instrument was designed to have multiple items aligning with one underlying trait) or item response theory101,102 to see if the items designed to capture consecutive levels of the trait along the continuum are doing a satisfactory job.
At this stage it is also necessary to consider the precision of the measurement. The observed score produced by an instrument should be close to the true score with low error. This is estimated by the internal consistency of a multi-item scale or questionnaire using Cronbach alpha coefficients or Kuder Richardson 20 if the scale is dichotomous (yes/no). Internal consistency is a feature of a scale with many items measuring the same thing. The responses should be similar across items within the instrument. It is not a feature of a scale containing weighted sums of different attributes such as disease activity measures.103 The internal consistency reliability can be converted back into the scale score by calculating the precision limits (using 95% limits, the true score is somewhere within 1.96 × s[1-r]1/2, where r = internal consistency and s = standard deviation). This identifies the range within which the true score for an individual will reside.
If more than one person will be gathering the data, inter-rater/interobserver reliability should be measured and quantified with an intraclass correlation coefficient (ICC) for continuous measures or a weighted Kappa for ordered categories.104 There are different types of ICC depending on the model used for the variance estimates. The type of ICC should always be named.104 The ICC and weighted Kappa measure the comparability of actual numeric scores and are preferred over correlation coefficients that look only for trends and not a direct match in number values. Cutoffs are always challenging, but in general reliability should be at a minimum 0.7593,100 for group-level analyses (where analysis is always done for a group of patients, as in the mean score comparisons in a clinical trial). For a description of an individual patient, ICC should be 0.90 to 0.95.93,100
Related posts:

Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


