CHAPTER 10 Outcomes Research for Spinal Disorders
Need for Outcomes Research
Outcomes research can be defined simply as “the measurement of the value of a particular course of therapy.”1 It is based on the principle that every clinical intervention produces a change in the health status of a patient that can be measured. The motivation for outcomes research varies depending on one’s perspective, but all parties involved in health care have a vested interest in defining outcomes related to medical interventions. Health care providers have a responsibility to provide the highest level of care to their patients, and this can be done only if the best treatment for a given condition has been determined through research. Patients need to be well informed about their prognosis, treatment options, and expected outcomes associated with each treatment option so that they can make a well-informed decision with their physician. Private and government payers have the right to demand evidence that the interventions for which they are paying yield improvement in the health of the patients they cover.
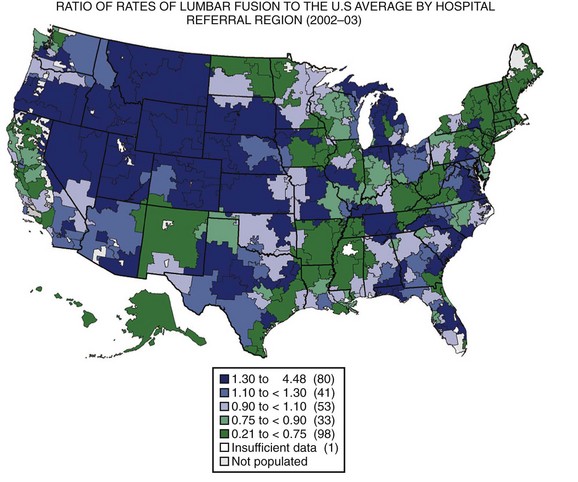
The United States has the highest gross domestic product (GDP) in the world and spends a higher proportion of its GDP on health care than any other country in the world, with little evidence to suggest that the level of public health is better than other developed countries.2,3 Wennberg and Gittelsohn4 developed the method of small area analysis in which variations in practice patterns, spending, and outcomes could be compared across hospital referral regions. They showed markedly different rates of hospital use between Boston, Massachusetts, and New Haven, Connecticut, for conditions without defined treatment protocols such as back pain, with no discernible differences in outcomes.5 Using the technique of small area analysis, Fisher and colleagues6,7 studied the relationship between Medicare expenditures and outcomes in hospital referral regions across the United States and found no relationship between the level of health care spending and outcomes. The substantial geographic variation in rates of lumbar surgery in the Medicare population was documented by Weinstein and colleagues (Fig. 10–1).8 These studies have shown that practice patterns vary substantially across different regions, indicating that the “best” practice for many conditions is unknown. The wide variation in the rates of health care use suggests that many regions are not practicing in the optimal zone of use, indicating that health services are likely underused in some regions and overused in others.
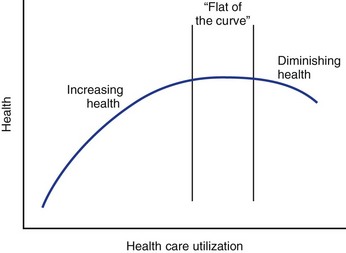
In the past, health care providers have assumed that increased use of health care services was associated with higher quality outcomes, a relationship that is shown by the upward-sloping portion of the curve shown in Figure 10–2. Economists have theorized, however, that eventually this curve flattens out such that additional expenditures yield increasingly fewer benefits until there is no marginal benefit (law of diminishing marginal returns).9 Although it has not been explicitly shown, it is possible that the curve eventually starts sloping downward, indicating that outcomes worsen with increasing use. Such a phenomenon could occur if patients were being inappropriately selected for treatment from which they were unlikely to benefit but might still experience treatment side effects. The Maine Lumbar Spine Study suggested that such a down-sloping portion of the curve might exist as outcomes for lumbar intervertebral disc herniation and spinal stenosis were worst in the regions where the rates of surgery were the greatest.10,11
Given the wide variation in practice across all of medicine and spine surgery in particular, policymakers have demanded that the research community perform outcome studies to determine the best practices for treating various conditions. In 2007, a Medicare Evidence Development and Coverage Advisory Committee (MedCAC) questioned the role of fusion for degenerative lumbar conditions in patients older than 65 years and suggested that Medicare could discontinue reimbursement for the procedure unless it could be shown to be effective.12 In response, Glassman and colleagues13 analyzed their results of lumbar fusion in this population and found that older patients had equivalent or better outcomes compared with younger patients. Although it is unclear how these data will be acted on, the MedCAC study and response to it provide an example of how researchers can respond effectively to policymakers who are looking for evidence to justify health care expenditures. As part of the 2009 economic stimulus package, more than 1 billion dollars was allocated for comparative health research, suggesting that outcomes and cost-effectiveness research are likely to play an increasingly important role in guiding health policy. This chapter introduces the spine surgeon to some methods of outcomes research, including outcomes measurement, study design, and cost-effectiveness analysis.
Measuring Outcomes in Spinal Disorders
One of the first principles of science is that you have to measure something, and a cornerstone of outcomes research is that any change in health status is measurable. Measuring subjective qualities such as pain and function, two important outcomes in patients with spinal disorders, can be quite challenging, however. In the classic literature, outcomes were often physiologic (i.e., motor function), radiographic (i.e., fusion), or subjectively defined by the treating physician (i.e., “poor,” “fair,” or “good”).14,15 Over the last 30 years, clinical studies have adopted patient-based outcome measures. Outcome measures can be classified as global measures of health (i.e., SF-36 Health Survey,16 EuroQoL,17 Sickness Impact Profile [SIP]18) or condition-specific measures (i.e., Oswestry Disability Index [ODI],19 Roland-Morris Disability Questionnaire [RDQ]20). High-quality outcome measures need to be practical, precise (reliable), accurate (valid), and responsive.21
In the medical literature, it is commonly held that many of the well-known generic and back-specific outcome measures have been shown to be practical, precise, valid, and responsive and can be considered “validated” outcome measures.22 From a psychometric perspective, much of this evidence is post-hoc, however, meaning that the instrument’s validity is based on its use in a study where the results showed that one group improved more than another by some statistically significant amount. By this logic, the fact that the tool “worked” (i.e., allowed for a statistically significant difference to be observed) is taken as de facto evidence that (1) the tool is practical because the patients completed it, (2) the tool is reliable because a significant difference between groups was observed, (3) the tool is valid because the goal of the instrument is to document the magnitude of an outcome that was expected to be different for the various treatment groups, and (4) the tool is responsive because the difference in outcomes was detectable. Subsequent studies use these same tools, often for different populations, justifying their use because the instrument has been “validated” in a previous study.
The Spine Patient Outcomes Research Trial (SPORT) intervertebral discs herniation (IDH) study serves as a good example to examine the selection of outcome measures. The primary outcome measures were the SF-36 bodily pain and physical function scales and the ODI (American Academy of Orthopaedic Surgeons MODEMS version), and secondary outcome measures included work status, satisfaction, and the Sciatica Bothersomeness Index.23 The distinction between the primary and secondary outcome measures was that the study was powered to detect a prespecified difference in the primary outcome measures (i.e., a 10-point difference on the SF-36 scales or ODI), whereas the secondary outcome measures did not factor into the power analysis. As has been recommended, SPORT included a generic (SF-36) and condition-specific (ODI) primary outcome measure.24 Given the extensive use of the SF-36, ODI, and RDQ in the spine literature, we examine these questionnaires in greater detail.
The SF-36 is among the most commonly used generic health questionnaires and has been extensively validated across many medical conditions.25 It consists of 36 questions and can be completed in less than 10 minutes. Responses are scored on eight nonoverlapping scales (physical functioning, role-physical, bodily pain, general health, vitality, social functioning, role-emotional, and mental health), which are summarized as a physical and mental component summary score. All scales range from 0-100 (lower scores represent worse symptoms), with the component summary scores transformed to have means of 50 and standard deviations of 10. In looking at the specific scales used in SPORT, the physical function scale is based on ratings of activity limitation (i.e., carrying groceries, climbing stairs, walking), and the bodily pain scale is based on two questions about the severity of pain and the degree to which pain interferes with work. At baseline, the patients in the SPORT IDH randomized controlled trial (RCT) had a mean baseline physical function score of 39.4 (age-adjusted and sex-adjusted norm of 89) and bodily pain score of 26.9 (age-adjusted and sex-adjusted norm of 81), suggesting they were markedly affected by their disc herniation.
The ODI was designed specifically for use in a back pain clinic and asks one question about the intensity of pain and nine questions about the degree to which pain limits specific activities (i.e., lifting, walking, traveling). Scores can range from 0-100, with higher scores indicating more severe disability. The mean score among “normals” is about 10, with mean scores in the 30s for patients with neurogenic claudication and 40s for patients with metastatic disease.26 In the SPORT IDH RCT, the average baseline ODI score was 46.9, indicating substantial pain-related disability.27 The ODI has been extensively validated and used in the spine literature and has been recommended to be used as a back pain–specific questionnaire (the Roland-Morris Disability Questionnaire is the other outcome measure recommended for this purpose).26
The RDQ is a 24-item survey developed from the 136-item SIP, with the phrase “because of my back” added to the end of the SIP statements to focus the survey on back-related problems.20,26 The questions focus primarily on function and pain, with only one question asking about the psychological effects of back pain and none inquiring about social function. Each question is a statement about the effect of back pain on function on the day the survey is taken (i.e., walking, bending, sitting, lying down, dressing, sleeping, self-care), with which the respondent must agree or disagree. The number of positive responses is the score (0-24), with median scores of 11 in a population with back pain presenting to a primary care clinic.28 The RDQ has been shown to be valid and responsive, although reproducibility has been difficult to show because it refers to symptoms only over a 24-hour period. In comparing the RDQ and the ODI, it has been suggested that the RDQ may be better able to detect changes in function in patients with a mild to moderate degree of disability, whereas the ODI may be better suited to patients with a more severe degree of disability.26
Experts have recommended using global health and back-specific outcomes questionnaires.29 The SF-36 or EuroQoL are recommended for measuring global health in spine patients, whereas the ODI or RDQ are the recommended back-specific instruments. In addition to these formal outcome measures, measuring work status and overall satisfaction with treatment is recommended.
Importance of Study Design in Outcomes Research
The goal of any outcomes research study is to measure results from a study sample and extrapolate those results to understand health outcomes in the real world. The results of research studies are highly dependent on the details of study design, however. Reviewing three RCTs comparing lumbar fusion with nonoperative treatment for chronic low back pain reveals one study that showed a clear advantage for surgery,30 one that showed only a minor benefit to surgery,31 and one that reported no benefit for surgery.32 How can three RCTs asking the same essential question come to three contradictory conclusions? The answer may reflect differences in research methods and details of study design. In designing or evaluating a research study, one must consider the research question, the target population and study sample, the interventions being compared, the outcome measures employed, and the specific study design.
When the research question has been specified, the next step is to define the target population and study sample. The target population is the group of people to whom the results of the study should be generalizable, whereas the study sample is the group of patients actually available for study.33 The target population is defined by the inclusion and exclusion criteria. There is an inherent struggle between having inclusion and exclusion criteria that are very restrictive yet provide a homogeneous study population (i.e., 34-year-old women with left-sided posterolateral L4-L5 disc extrusions and extensor hallucis longus weakness) and criteria that are less restrictive and yield a more diverse study population (i.e., anyone with a disk herniation). More restrictive studies can specifically evaluate the effect of treatment on specific patient subgroups, whereas less restrictive studies are inherently more generalizable. Defining subgroups that have different outcomes is important to determine the best treatment for individual patients, although it is not usually possible to perform separate trials for each subgroup.34 Understanding the actual target population is essential to interpreting and acting on the findings of a study.
Most clinical studies evaluate the effect of an intervention on an outcome.35 Similar to the study participants and outcome measures, the intervention also needs to be clearly defined. The intervention for the control or comparative group also needs to be specified. Differences in the experimental and control interventions may explain some of the differences among the aforementioned studies comparing fusion with nonoperative treatment for the treatment of chronic low back pain. Fritzell and colleagues30 compared three types of fusion techniques with nonspecific physical therapy and showed a clear benefit to fusion. In contrast, Brox and colleagues32 compared instrumented posterolateral fusion with a very specific program of cognitive therapy and 3 weeks of intensive physical therapy and reported no differences in results. These two studies did not compare the same interventions, and this may be one reason for the discrepant results.
The specific study design used by a research project can have profound effects on the interpretation of the results. Each study design has inherent advantages and disadvantages that must be weighed when planning an investigation. Although the RCT is considered the “gold standard” of clinical research designs, it is often the case that mounting an RCT before the preliminary case series, case-control, and cohort studies have been performed would be counterproductive. The high cost in terms of researcher and clinical time often greatly outweigh the results obtained from a poorly planned RCT. Before launching a large RCT, observational pilot studies should be performed to generate hypotheses and reveal challenges (e.g., adequate assessment, compliance with treatment, treatment harms and side effects) that are difficult to anticipate. A unique aspect of the study design of SPORT was its concurrent use of an RCT and observational cohort study that allowed patients to choose enrollment in the randomized or observational arms.36 Before discussion about the merits and problems associated with each specific study design, we consider the general threats to the validity of a study.
Understanding Threats to Study Validity
Generally, threats to study validity have been classified as internal and external (Table 10–1). Internal validity is related to the validity of the conclusions of a study within the study sample—was the observed difference between the treatment groups real? External validity refers to whether or not the findings of the study can be generalized to populations and settings outside of the study sample—would the difference observed in the trial be observed in the real world?
TABLE 10–1 Internal and External Validity Threats
| Internal Validity Threats | External Validity Threats |
|---|---|
| History: Specific events occurring between first and second assessment in addition to experimental variable | Selection bias: To the extent that patients presenting at study sites are not representative of patients in general |
| Maturation: Processes within patient operating as a function of time (e.g., favorable natural history) | Reactive or interactive effects: Screening process (informed consent, extra attention, additional procedures to identify inclusion/exclusion criteria) is not done with nonstudy patients |
| Testing: Effects that testing itself has on subsequent scores | Reactive effects of experimental procedures: Just being in a study may affect patient responses |
| Instrumentation: Changes in obtained measurements owing to changes in instrument calibration, observers, or raters | Multiple treatment effects: When treatments have multiple components (i.e., surgery, postsurgical rehabilitation) or when patient has multiple treatments (i.e., nonoperative treatment followed by surgery), possible effects of former treatment on latter may influence efficacy |
| Statistical regression: Lack of reliability in tools, which is especially problematic when patients are selected on basis of extreme scores | |
| Selection: Biases resulting from differential selection of patients into treatment arms | |
| Patient attrition: Differential loss of patients from treatment groups (e.g., loss to follow-up, crossover) | |
| Interactions of above effects: Interactions among above variables may have effects that are mistakenly attributed to treatment |
Clinical studies generally aim to determine if a specific intervention results in a certain outcome. Although a study may show an association between an intervention and an outcome, this association may be spurious (i.e., the association exists in the study but not in the real world), or the association may not represent a cause-effect relationship (i.e., the intervention was associated with but was not the cause of the observed outcome). The two main causes of spurious associations are chance (random measurement errors) and bias.37 Confounding is another threat to validity that can obscure the cause-effect relationship between the intervention and outcome being studied. Different types of study designs are prone to different types of inferential errors, and this is discussed in detail when each study design is considered.
Chance
When an association is observed between an intervention and an outcome, it is possible that this observation is due to chance rather than to the intervention causing the outcome. Fritzell and colleagues30 reported that fusion for chronic back pain reduced ODI scores by 11 points, whereas nonoperative treatment resulted in only a 2-point decrease. Although surgery effectiveness may have been responsible for the difference, it is also possible that surgery had no beneficial effect and that the observed differences were due to chance alone. Statistical tests are used to evaluate the possibility that an observed relationship between an intervention and outcome was due to chance. In the case of the study by Fritzell and colleagues,30 statistical testing showed a statistically significant difference (P = .015), indicating that the association between surgery and symptom improvement was probably real. Details about the theories underlying probability testing are beyond the scope of this chapter and can be found in standard biostatistics textbooks.38
Related posts:

Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


